This Food Does Not Exist 🍪🍰🍣🍹🍔
We trained StyleGAN2 models to generate food pictures. The images below are all synthetic!
This work was done by Martin Müller and Florian Laurent in partnership with the Food & You project by the Digital Epidemiology Lab at EPFL. In this context, we are researching the potential of synthetic data augmention for vision tasks.
This research is part of the technology underlying our AI-generated photography platform Nyx.gallery. You can also follow our work on 🐦 Twitter.
The code optimized for TPU training as well as the pretrained models are openly available.
Multi-class 512x512 model 🆕
Release v0.2, October 2022

food-512.pkl
We have released a new and much improved model:
- Single 5-class model (burger/cheesecake/cocktail/cookie/sushi) instead of 1-class models
- Resolution of 512x512 instead of 256x256
- Trained for much longer: 8 days at 256x256 then 28 days at 512x512 on a TPU v4-8
- Trained on more data: 558k 512x512 images instead of 100k 256x256 images
🍒 The sample above are cherry-picked: check out the Colab notebook to generate your own, or train your own model.
Single-class 256x256 models
Release v0.1, July 2022
The models below were released in July 2022. Each model was trained on a single food class: cookie, cheescake, cocktail and sushi. They can still be used with the v0.2 code.

cookie-256.pkl

cheesecake-256.pkl

cocktail-256.pkl

sushi-256.pkl
Why not DALL·E/diffusion models? 🤔
Recent methods like diffusion and auto-regressive models are all the rage these days: DALL·E 2, Craiyon (formerly DALL·E mini), ruDALL-E… Why not go in this direction?
Realism vs control
StyleGAN models shine in terms of photorealism, as can be some by some of our food results. For another example, the website ThisPersonDoesNotExist.com produces very believable face images. While GANs are still better at this, diffusion models are catching up and this may change soon.
Diffusion models offer better control and flexibility, thanks in large part to text guidance. This comes at the cost of larger models and slower generation times.
Training resources
We were able to train the provided models in less than 10h each using a single TPU v4-8:
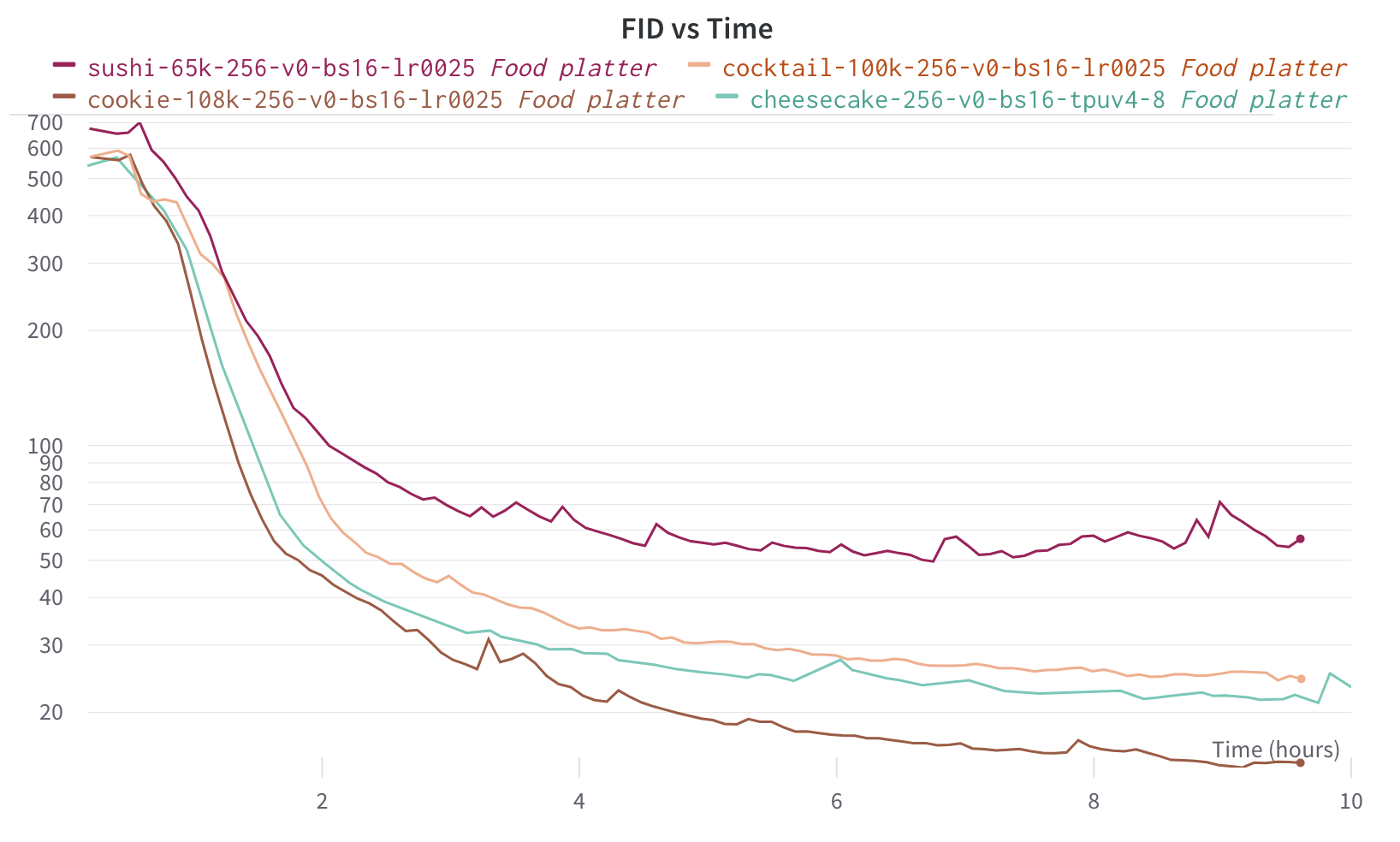
FID (Fréchet inception distance) is a metric used to assess the quality of images created by a generative model.
In comparison, Craiyon is being training on a v3-256 TPU pod which means 32x the resources (albeit using the previous TPU generation) and the training has been going on for over a month.
Result comparison
No cherry-picking!
Ours

Craiyon (“a pile of cookies on a plate”)

DALL·E 2 (“a pile of cookies on a plate”)

Acknowledgements 🙏
- This work is based on Matthias Wright’s stylegan2 implementation
- The project received generous support from Google’s TPU Research Cloud (TRC)
- The image datasets were built using the LAION5B index
- We are grateful to Weights & Biases for preserving our sanity
Follow our Generative AI research: 📘 GitHub 🐦 Twitter 📩 Newsletter 👨💼 LinkedIn 📷 Instagram